Airflow, the orchestration system which has become an instant hit in the data engineering world, is one of the most beloved technologies by SimilarWeb engineering. In this post, I’ll use Airflow’s example to show how crucial it sometimes is to choose the right abstractions and their semantics.
Interestingly, the last two orchestration systems that I worked with before Airflow didn’t incorporate a real scheduler. That means that in order to routinely run a daily workflow, for instance, one should have triggered the workflow with an external scheduling system (I recall crontab, Rundeck and Jenkins being used). Namely, I’m referring to Spotify’s Luigi (that was in use in my previous workplace) and SimilarWeb’s legacy home-grown orchestration system that was not open sourced. Both managed task dependencies within the workflow and triggered tasks to run once their dependencies have been met. However, they did not trigger the workflows to start in the first place.
Why were they designed this way? Does it make sense to avoid workflow scheduling in an orchestration system? Well, there’s actually a solid logic behind it. According to the principle of separation of concerns, why should one implement a piece of logic, if there’s already a well-maintained product already doing that. One may argue that introducing a schedule is equivalent to recurrently triggering a workflow to start, each time with a different date argument. Say that we have a daily schedule firing every day at 00:00. We would only need to spawn the same workflow every day, parameterized by date, and we’re done. According to this approach, we treat time as yet another parameter, and we may decouple the scheduler and the orchestrator to have a more tightened, coherent orchestration system. Moreover, it’s more general in the sense that some workflows should not have a schedule at all.

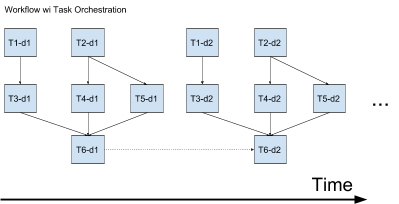
However, Airflow’s abstractions are aware of the schedule’s time dimensions. It knows that the various instances of the workflow that corresponds to the different runs according to the schedule are part of a single entity. Consequently, it has a fully-fledged scheduler built-in. Following is a figure that demonstrates the difference between the two approaches. Above is a system like vanilla Luigi which is aware of and triggers only tasks. Below is a system like Airflow which triggers both workflow instances and tasks. In the figure, T stands for task, d stands for day, and an arrow is a task’s dependency.
It’s immediately noticeable that the former is simpler. And, as a general rule, the simpler – the better. Again, it’s easy to see that the core functionality of the latter can be achieved by spawning recurring instances of the workflow with an external system. That being said, I would argue that the latter actually makes more sense, and by taking the time dimension into account in the abstractions, Airflow gained huge advantages over Luigi and opened the door to killer features.
For starters, let’s look at the figure above. There’s this dotted arrow that I haven’t yet explained. Well, this is a special kind of dependency, usually seen between consecutive instances of the same task, a dependency “on the past”. It’s very useful at times, as there are many algorithms which are fed with their own past output. This kind of dependency cannot be modeled in the former, simpler model, but in Airflow it’s natively baked in.
Then, there are backfills and reruns. If you take into account that the state of tasks is owned and maintained by the orchestration system, how can you efficiently do a rerun that starts at a certain time in the past, given that there are dependencies on the past? It turns out to be a nightmare in vanilla Luigi. But in Airflow, it’s as simple to apply as a single click in the UI that clears the future downstream of a certain task instance.
Moreover, there are super-useful visibility tools that you get out of the box in Airflow, which rely on the time-related abstractions. Below, you can see an example screenshot of a day over day task-duration chart, courtesy of the Airbnb blog. Other important types of charts, like a Gantt chart that lets you identify bottlenecks, are available as well.
So, how is this model actually implemented in Airflow? Without getting much into detail, in airflow there’s a distinction between the topology and definition of a workflow. They are all statically defined with abstractions such as “task” and “DAG”, and the runtime abstractions “task-instance” and “DAG-run”, which have the special execution date property corresponding to the di labels in the first figure. The runtime abstractions are the ones that are actually being run, and whose state is book-kept. Note that the schedule is very flexible and can be set to all sorts of intervals. Actually, anything that can be expressed in crontab syntax is supported, and even some fancy schedules, like ‘once’ or ‘never’.
As illustrated in the sketch below, many design choices tackle the tradeoff between generality and specialization, and it’s a tough choice to make. In our context, Airflow went for a more specialised model, with sharper semantics and bigger complexity. I think that they hit the sweet spot and that it paid off big time.

To conclude, Airflow was designed to have the schedule’s dimensions included fully in its abstractions. Consequently, it had a fully-fledged scheduler right from start. This clearly allowed it to naturally incorporate crucial features that are time-related, which are virtually impossible to have in orchestration systems that leaned on a simpler, more general model. This is a good example of a winner design choice.
About the Author:
Iddo Aviram is a Principle engineer in SimilarWeb, formerly system architect in Totango.
MSc in computer science from Ben Gurion University of the Negev.