Databricks and Amazon’s Athena are two very powerful trending tools for Big Data analysis over Amazon’s S3 storage solutions, each with its own unique quality. They allow Big Data engineers, researchers and analysts to access and analyze data stored on Amazon’s S3 using either SQL or Spark code (written in Python or Scala).
A quick recap – DataBricks
According to their website, Databricks is a “Unified Analytics Platform, from the original creators of Apache Spark™, that unifies data science and engineering from data preparation, to experimentation and deployment of ML applications.”
Essentially, Databricks is a platform of Python/Scala notebooks (like the well-known IPython spin-off, Jupyter Notebook), running on an on-demand, cloud-based cluster service that you can customize based on your needs including auto-scaling, choosing machine types, scheduling up/down times, and much more. Databricks notebooks also support a wide array of features like job scheduling, custom importing of Python libraries, JAR files, creating custom UDFs, running SQL queries (on its own Hive metastore), its own file system (DBFS) and lots of other cool tools that allow you to have everything you need in one place for your advanced analytics. They even have their own optimized version of Spark that is specifically suited for Databricks running under the hood.
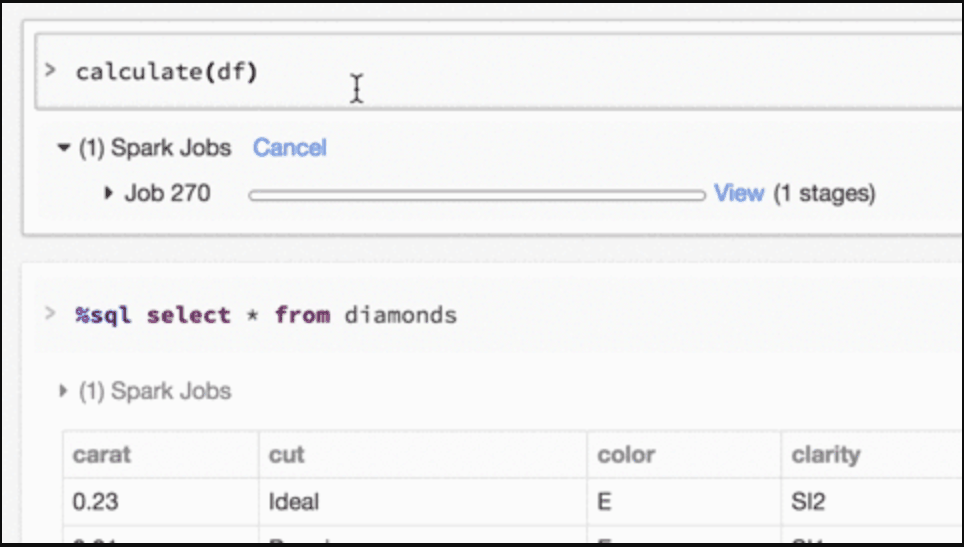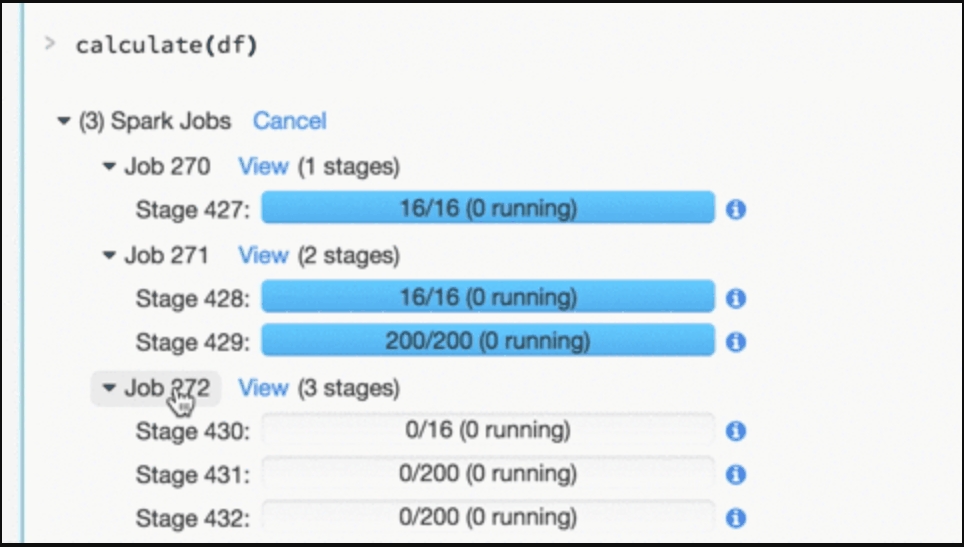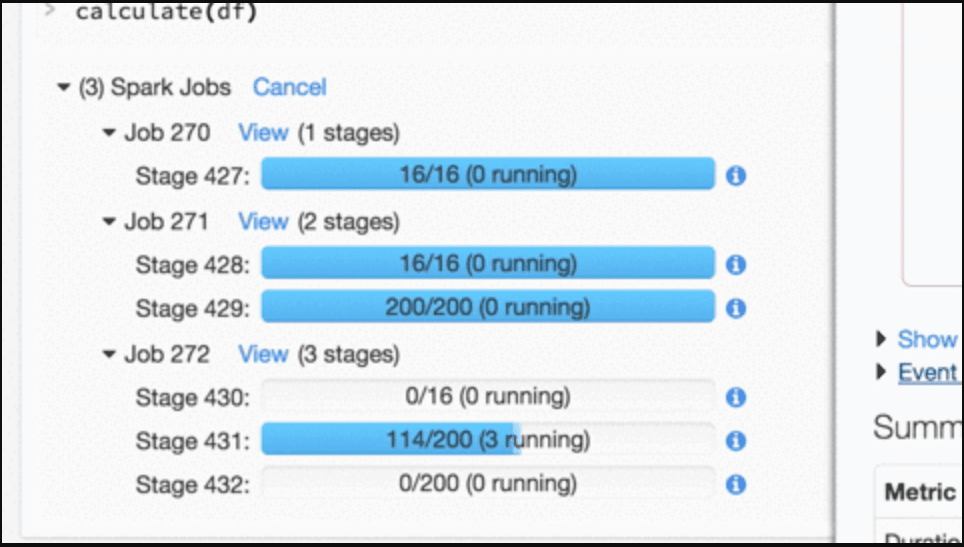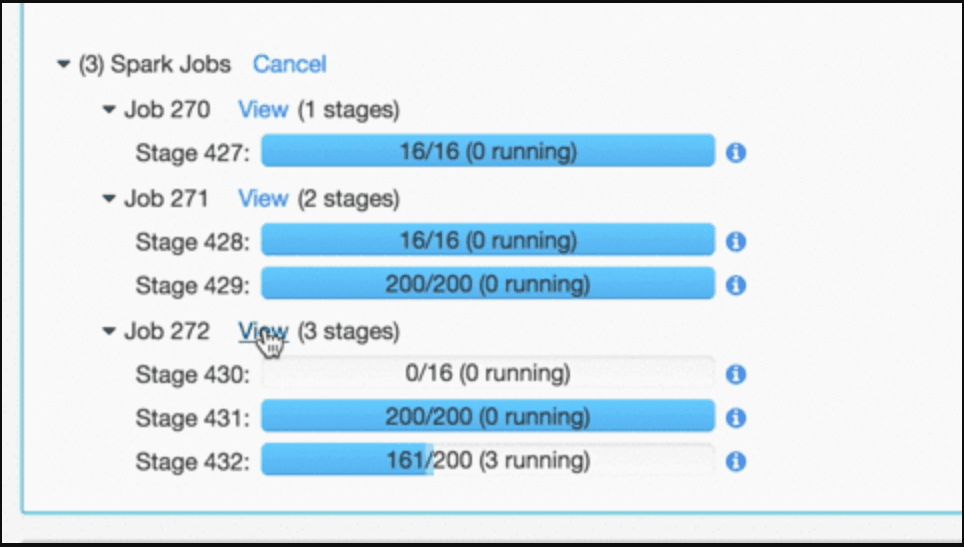
Databricks notebooks are also HTML-based, which allows you to present your data within the notebook without importing any special libraries or knowing too much about what you are doing.
What about costs?
Databricks charges $X per machine, per hour (billing is given on a per second granularity), leaving some wiggle room for clusters’ auto-scale features, amount of machines you keep alive by default, use of spot instances and more.
But cloud vendor charges need to always be taken into consideration whether you choose to keep your data on Amazon S3 or Microsoft’s Azure, you will need to keep an eye out for storage and run costs on the cloud vendor’s side as well, as paying for Databricks and the cloud vendor could reach a significant amount each month.
For example, if you pay $0.20 per machine, per hour and you have a cluster that has 100 machines that are constantly running– you will end up with a monthly bill of $14,400. This means you need to be smart about how you manage your cluster – using tricks like auto-scaling, shutting down clusters on downtime, using spot instances and optimizing your analytics to make sure you run with the least amount of machines possible, for the shortest amount of time.
A quick recap – Amazon’s Athena
Amazon’s Athena is a tool that enables you to easily utilize a Presto-based SQL solution (using Hive-based Structured Query Language (HQL) and the Hive’s metastore) on data stored directly on S3 to analyze large data sets with ease using familiar and steady Big Data serverless technology.
And while Athena may be a one-dimensional solution, (i.e. Set a table over your data; Query it using SQL; get results and get out), what it really is, is fast! I mean really fast. In the example below it ran a query over ~4Gb of data within roughly 5 seconds. No cluster sizing, no job submission, no monitoring of any kind on the infrastructure – Pure, serverless, good quality SQL run time on huge amounts of data.
Athena can also be reached using JDBC and the Athena API to execute queries over your data – as I will demonstrate below.
And Costs?
In short, Amazon Athena says “Don’t worry about infrastructure, we’ve got you covered” but you will be charged per amount of data scanned. The cost is $5 per Tb of data scanned, with a minimum of 10Mb of data charge per scan.
Ok, So how can we make the best out of both worlds?

Well, we’ve established Databricks is diverse, but slower. while Athena is single-minded but speedy! All that’s left to do, is combine them into one mean analytics machine with Amazon Athena’s API.
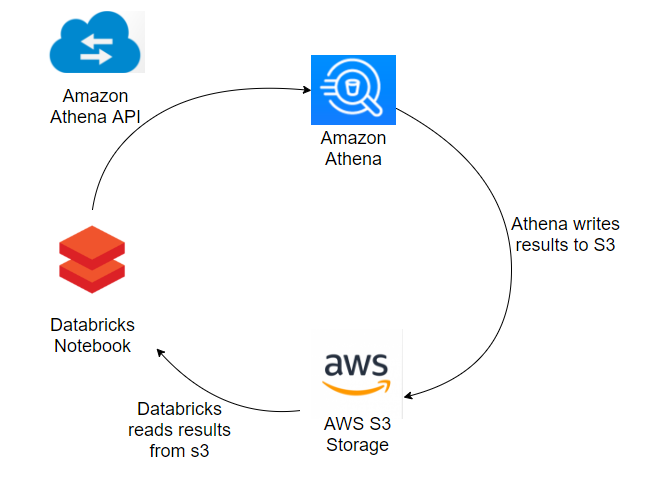
How to run Athena queries using Databricks – Overview
Databricks’ notebooks can send API requests outside of Databricks and retrieve data back. The idea is to create and execute the queries that would take significantly more time to run on Databricks, in Athena. This is done via the Databricks notebook using Athena’s API before returning the results into a Spark DataFrame within the notebook. This will save both time and money by avoiding Databricks’ cluster managing.
This takes advantage of the fact that Athena queries have a “default storage location” on S3. Each query is given a unique identifier that saves a single file on S3. Allowing you to pull that data back to Databricks once the query has finished running.
Here is a sample code of how you can do that.
Within the Databricks notebook, you will need to import the following libraries. Note that boto is the library that will allow you to connect to the Athena API. Make sure you have the most up-to-date version.
Now you can get the data you need with four simple steps:
- Set up a connection to Athena and S3
- Send the query to Athena
- Wait for the query to finish (using the response status). I’d advise iterating every second to check the status.
- Once the status is “SUCCEEDED” you can now read the output file generated by Athena on S3 into a Spark DataFrame
Step by step code snippets on how to execute each step in the Python notebook on Databricks:
Step 1: Set up a connection to Athena and S3
Step 2: Send the query to Athena
Step 3: wait for the query to finish (using the response status). I’d advise to iterate every second to check the status.
Step 4: once the status is “SUCCEEDED” you can use the OutputLocation parameter to read the output file generated by Athena into a Spark DataFrame
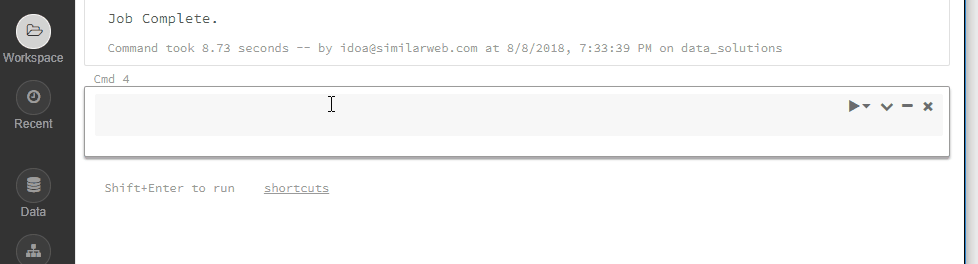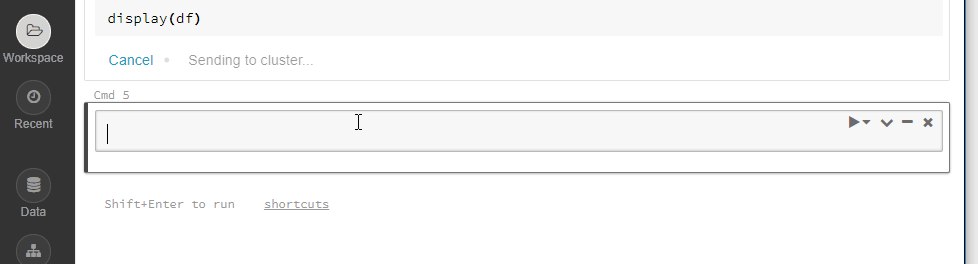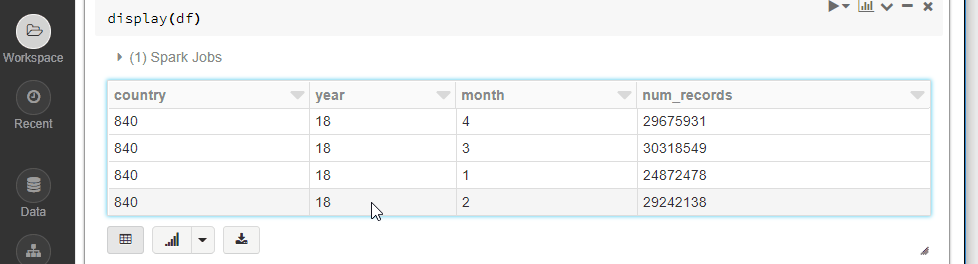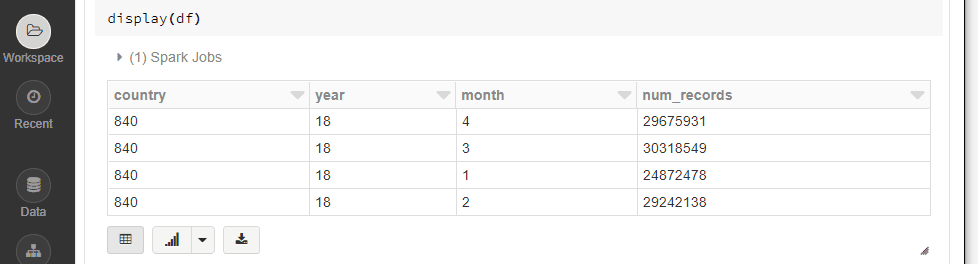
That’s it! now you can use the Spark DataFrame in Databricks as you please
Summary
Specifically for SQL queries, using Athena’s speed to reduce the amount of time and machines you are using in Databricks is a pretty nifty way to reduce overall Databricks’ monthly costs. There are still limitations and some small tweaks you will encounter with this solution, whether it’s the Presto SQL that Athena is using which does not support all operations like building Custom UDFs), or trying to return too much data from Athena at once.
The goal is to find the right balance between the two and juggle between them wisely. This could save you not only money, but precious time, such as getting the results for the same query in 40 seconds instead of 40 minutes.