NoSQL databases are a great fit for many modern mobile, web, and gaming applications that require scalable, flexible, and highly functional databases. However, NoSQL databases by their distributed nature can be difficult to manage, especially at scale, and can require many resources and a lot of attention. For several years, SimilarWeb operated two Couchbase clusters, but the cost and operational overhead were high. To improve stability and reduce cost and operational overhead, SimilarWeb migrated to Amazon DynamoDB. DynamoDB is a fully managed database service that is now one of the authoritative databases to serve data to SimilarWeb’s customers in multiple AWS Regions.
In this blog post, we detail why SimilarWeb chose to migrate to DynamoDB. We also describe their migration process and show the optimizations that they made to help reduce costs.
About SimilarWeb
SimilarWeb is a market intelligence company that provides insights about what is happening across the digital world. Thousands of customers use these insights to make critical decisions about how to improve strategies in marketing, drive sales, and make investments. The importance of the decision-making that SimilarWeb empowers emphasizes their capacity to collect and use data effectively and eventually serve it to users.
SimilarWeb continuously collects and ingests high volumes of raw data from a variety of sources. They sort and structure this data using a Cloudera cluster running Apache Spark. They load the data into Apache HBase clusters and store it in an Amazon S3–based data lake. In the past, part of the data was loaded to Couchbase clusters, which they later migrated to DynamoDB. This blog post focuses on this migration.
After the migration, SimilarWeb uses the data in HBase and DynamoDB for serving insights to their customers from two AWS Regions. For more information about SimilarWeb’s multiregion-serving architecture, watch this episode of This is My Architecture.
Why SimilarWeb migrated from Couchbase to DynamoDB
Couchbase is a distributed, nonrelational, document-oriented database that is optimized for interactive applications. Before the migration, Couchbase’s role was to enrich static data coming from HBase with dynamic data that changes more frequently.
Amazon DynamoDB is a nonrelational database that delivers reliable performance at any scale. It’s a fully managed, multiregion, multimaster database that provides consistent single-digit millisecond latency, and it offers built-in security, backup and restore, and in-memory caching.
SimilarWeb decided to migrate to DynamoDB because of several challenges they faced with their Couchbase deployment.
Operational overhead
Maintaining Couchbase clusters added significant overhead and required specific experience and knowledge. Ongoing maintenance operations such as server and database patching, upgrades, monitoring, and keeping the database high-performing consumed valuable time. Maintaining Couchbase clusters in two AWS Regions increased the operational overhead even more.
Because DynamoDB is a fully managed service, SimilarWeb software engineers could focus on business innovation rather than on managing and maintaining database operations and infrastructure.
Availability
On at least 10 occasions over 2 ½ years, the SimilarWeb Couchbase database was either partly or fully down. In the 10 months since migrating from Couchbase to DynamoDB, SimilarWeb’s database has seen 100 percent uptime.
Performance
SimilarWeb struggled to get consistent response times from Couchbase because their dataset was too large to fit in RAM, and therefore Couchbase’s advantages were not applicable. With DynamoDB, they see lower and more consistent query response times.
The following two graphs show the average response times from Couchbase and DynamoDB as seen by SimilarWeb’s servers. The queries represented in the graphs include requests for multiple keys.
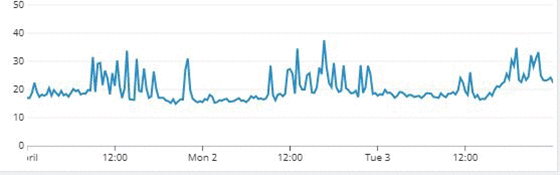
Graph 1 shows a higher baseline latency of about 18 milliseconds with Couchbase, compared to about 13 milliseconds with DynamoDB in Graph 2.
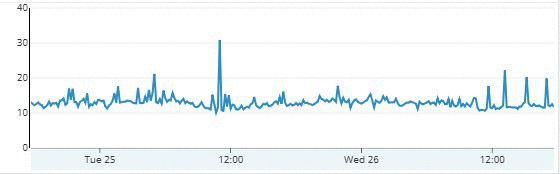
In addition, the DynamoDB graph (Graph 2) shows a smaller deviation from the baseline and fewer spikes than with Couchbase.
Segregation of production and test environments
To reduce operational overhead and cost, SimilarWeb used the same Couchbase clusters for both production and staging environments, a situation in which tests could affect production workloads. With DynamoDB, each table has its own provisioned capacity, so queries that run against one table don’t affect queries that run against other tables.
Cost
The Couchbase clusters were overprovisioned to support traffic spikes. With DynamoDB, the write and read capacities are defined separately for each table. You can adjust these capacities manually or with DynamoDB auto scaling based on actual usage. SimilarWeb uses these abilities to pay only for the required capacity and reduce their database costs by more than 70 percent.
For more information about how SimilarWeb achieved this cost reduction, see the next section.
Migrating to DynamoDB
SimilarWeb needed to quickly populate daily and monthly tables with hundreds of millions of records in two AWS Regions. In this section, we show how SimilarWeb managed to achieve this while remaining aware of costs.
Handling dynamic write and read requirements
SimilarWeb has configured DynamoDB to scale write and read capacities differently to optimize each for their workloads, which was not an option in Couchbase. For example, during daily and monthly jobs that insert data into the DynamoDB tables, the tables need to handle very high write throughput. During other times, writes are not performed against the database, and the tables are used only for read workloads.
SimilarWeb uses the ability to tune the provisioned write capacity of a DynamoDB table dynamically using a script. The script raises the write capacity for the duration of the data insertion and reduces it back to the bare minimum as soon as the insertion is completed. Auto scaling isn’t used in this case because it can’t scale the provisioned write capacity fast enough to handle the rapid changes in the number of writes done against the table. They could have switched the tables to use on-demand mode and not worry about automatically scaling the writes. However, because their write workload’s access patterns are very consistent, provisioned mode plus their script is more cost effective and allows them to control the writes and reads independently.
SimilarWeb enables auto scaling for their tables’ read capacity to scale the capacity up and down automatically based on actual usage. DynamoDB burst capacity accommodates sudden traffic spikes by taking advantage of the unused provisioned capacity from the last 5 minutes.
Inserting data into DynamoDB in multiple AWS Regions using Amazon EMR
After the data is ingested from millions of clients and then processed and transformed, it is stored in an Amazon S3–based data lake. Before SimilarWeb migrated to DynamoDB, daily and monthly extract, transform, and load (ETL) processes inserted data into Couchbase so that it could serve queries from their website.
To insert vast amounts of data quickly from Amazon S3 to DynamoDB, SimilarWeb uses Amazon EMR, which provides a managed Hadoop framework that facilitates data insertion in a distributed manner. SimilarWeb used the emr-dynamodb-connector open-source library, which lets Hadoop, Hive, and Spark on Amazon EMR interact with DynamoDB.
To avoid latency and increased data transfer costs when serving traffic from two AWS Regions, the data resides in DynamoDB tables in both Regions and is queried in each Region locally. SimilarWeb could have used DynamoDB global tables, which provide a multiregion, multimaster database solution to replicate data between Regions. However, SimilarWeb chose to use a regional DynamoDB table in each Region instead (we explain why later in this post).
To ingest data into DynamoDB, they create new daily or monthly tables in the us-east-1 and us-west-2 Regions with high provisioned write capacity units (WCUs) and auto scaling for reading capacity units (RCUs). They start Amazon EMR clusters in both Regions, and submit a Hive job to each cluster to populate new tables with data.
After the data population finishes, WCUs for the new tables are reduced to one, which is the minimum allowed write capacity for a table. The Amazon EMR clusters are then terminated, and the serving applications switch from the old to the new DynamoDB tables. SimilarWeb keeps the old tables for backup for an additional day or month so that they can revert to them immediately if they identify an issue with the newly ingested data. The older tables’ read capacity is lowered to one, and tables older than two days or months are deleted.
Speeding up table creation
The initial procedure for creating a daily or monthly table in DynamoDB was to create a table with default capacity units and then update it by assigning the required WCUs and RCUs. SimilarWeb noticed that this process could sometimes take more than an hour. By instead including the capacity unit values in the table creation command, they reduced table creation time to several seconds.
The explanation to such a drastic reduction is related to how DynamoDB partitions data. Creating an empty provisioned capacity table with the default capacity units assigns a single partition to the table. This then causes a repartitioning upon updating the table’s RCUs and WCUs. Table repartitioning is a slower process compared to pre-partitioning the table when it’s created.
Reducing database costs
DynamoDB offers a variety of capacity models to address different use cases. In this section, we show how SimilarWeb chose the optimal capacity models for their specific use case and how they performed additional cost optimizations.
The DynamoDB capacity modes and which one SimilarWeb uses
A DynamoDB table has one of two capacity modes: provisioned or on-demand. When you create a table, you must choose one of the two modes (you can’t mix the modes in the same table, but you can change the mode every 24 hours).
With provisioned capacity mode, you can provision your table with the read and write capacity that you expect your database to require. And you can use auto scaling to let DynamoDB scale up and down the capacity as needed. For more information about provisioned capacity mode, see Provisioned Mode in the Amazon DynamoDB Developer Guide. You can also purchase reserved capacity for DynamoDB, which offers significant savings over unreserved provisioned capacity (up to 77 percent).
With on-demand capacity mode, DynamoDB charges for exactly the number of reads and writes performed on the table. To read more about on-demand capacity mode, see On-Demand Mode in the Amazon DynamoDB Developer Guide.
SimilarWeb’s customer activity initiates reads. And although reads might be spiky at times, they maintain a steady baseline usage over time. SimilarWeb purchased reserved capacity for reading capacity. They rely on auto scaling to handle gradual changes in traffic and on burst capacity to handle random spikes. For writes, they manage to scale with a script to make very fast changes for their use case and save money.
Other cost reductions
SimilarWeb’s workflow requires serving data from two AWS Regions, so they considered global tables to write data to one Region and replicate it to the other Region. Replicated write capacity units (rWCUs), which are used with global tables, cost more than regular WCUs. Because writes to the tables are only done once after the table is created, global tables features like writes conflicts resolution aren’t required. To reduce the solution’s cost, SimilarWeb chose to use regular tables in both Regions. As a result, data is ingested separately from an Amazon EMR cluster in each Region.
SimilarWeb reduced costs further by using Spot Instances in their Amazon EMR clusters. They also use Apache Airflow to spin up and down transient Amazon EMR clusters only for the duration of their ETL jobs.
Conclusion
In this post, we discussed how SimilarWeb migrated from Couchbase to DynamoDB. In the process, they reduced their database costs by more than 70 percent, improved performance, and reduced operational overhead.
About the author:
Doron Grinzaig is a Software Engineer in SimilarWeb’s “Platform” R&D group, working on digesting, transforming-loading and serving Big-Data.