Two and half years ago, back in 2016, all of our infrastructures were hosted in a dedicated, on-premise datacenter somewhere in the US. Our company was growing fast and was continuously releasing new services, algorithms and processing Petabytes of data. We were also waiting for the data center engineer to see our email, find a server with the required specs, install the operating system and then hand it back to us to continue the bootstrapping process. That’s a long waiting time, which we usually can’t afford.
This also applies to upgrading, decommissioning or investigating a faulty server.
We decided to migrate to the cloud in order to reduce our time to market, increase availability and alignment with the industry. Us all being engineers meant that we wanted to treat our infrastructure using the same methodologies and tools as the rest of our code base.
Infrastructure as Code
We are strong believers in the Infrastructure as Code methodology and love the fact that we can reuse code, educate our developers to use it and eventually be able to look at a Git commit when we need to investigate a faulty service.
Our vision is to have our entire infrastructure described and defined in code, deploy faster and safer – and support our R&D needs.
Even though the market has a few tools to offer, most of them are vendor specific. For the sake of flexibility, and our love for open source, we chose to use Terraform as our tool.
What is Terraform?
Terraform is a tool by HashiCorp that, “enables you to safely and predictably create, change, and improve infrastructure. It is an open source tool that codifies APIs into declarative configuration files that can be shared amongst team members, treated as code, edited, reviewed, and versioned.”
TL;DR – Terraform allows us to create pieces of code that will be reflected as actual infrastructure and eventually gain full ownership of our infrastructure and the ability to scale fast.
Our Challenges
SimilarWeb is currently being served from two AWS regions in an Active/Active setup and we have the ability to failover from either region without impacting our users. Our infrastructure in numbers:
- ~200 Route53 Zones
- ~1000 EC2 Instances
- ~800 Security Groups
- ~250 Load Balancers, ingesting hundreds of thousands of requests per second
- ~120 R&D Engineers
- PB’s of data, massive Hadoop clusters, etc.
Terraform implementation:
At first, we started by creating building blocks for each resource we use
(e.g. network subnets, RDS, S3 buckets, IAM entities, etc.).
The main purpose was to write code we can reuse, thus creating small, composable modules that do a very specific thing. This allowed us to have consistency throughout the environment, where each instantiation (usage) of the module does the same thing but with different values.
Here’s an example of an application load balancer (AWS ALB) module:
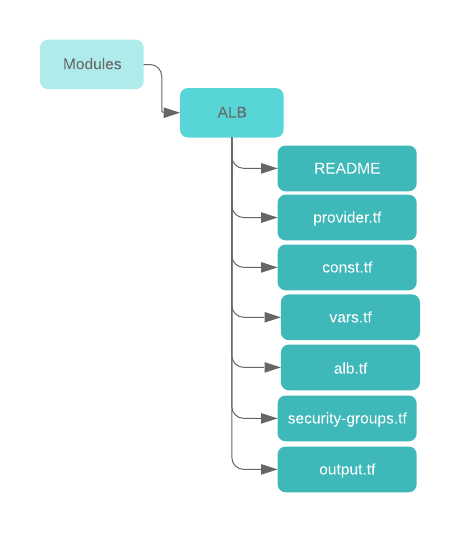
The structure is generic and can fit common use-cases:
- README.tf – Information about this module, how to use it and when.
- provider.tf – The provider this module is using. (see providers)
- const.tf – These variables are constant, as we don’t want anyone to change them, which is how we enforce policies and conventions.
- vars.tf – These variables are dynamic and differ for each usage of the module.
- alb.tf – This is the actual usage of the “aws_alb” terraform resource and that is where all of the variables (vars.tf) will end up.
- security-groups.tf – The “aws_security_group” resources
- outputs.tf – These are the variables and data that we want to expose to the state who will eventually use this module. This is the way to pass dynamic configurations (route53 zone_id, alb ARN, etc.) to the outside state for further usage.
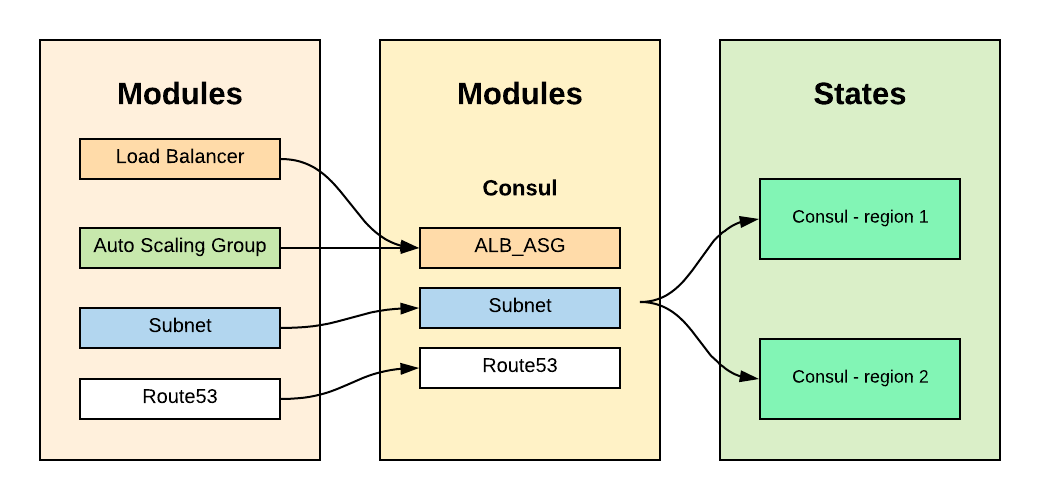
After having a building block for ALB, we can use it as part of a bigger module that represents a service with an ALB, as well as a Route53, EC2, and others.
Here is an example of how we reuse small building blocks (modules) to create services (big modules that are made up of small modules). In this case, we have two of HashiCorp’s Consuls across two regions that are using the same building blocks, just with different variables. In this case, the variable is the AWS region where it is running.
Today, our Terraform environment consists of:
- ~70 Building blocks (modules)
- ~500 States
- ~7,500 Resources
But, as you know, everything is a trade-off. In our case, there were two big issues that we needed to address:

Issue #1 – State is not aligned:
While writing new code and creating new infrastructure, it’s not rare to see an unapplied change to an existing infrastructure due to these reasons:
- A developer applied the changes from their local branch and not from the master branch (i.e. applying without merging).
- Sometimes, manual changes do occur in our production environment. Either it’s for the quick resolution of a production incident, to test a change or just to experiment with a new resource.
- Our culture enables our engineers to take full ownership over their services. This requires them to have full access to their resources and the ability to do manual changes, not via Terraform.
Since we are a data company, we have decided to tackle this problem with a data-driven approach. How big is the problem? How many manual changes do we have?
How many manual changes we have?
In order to quantify our hypothesis, the quick solution was to create a lambda function to ingest and analyze all of the changes that occur in our production environment.
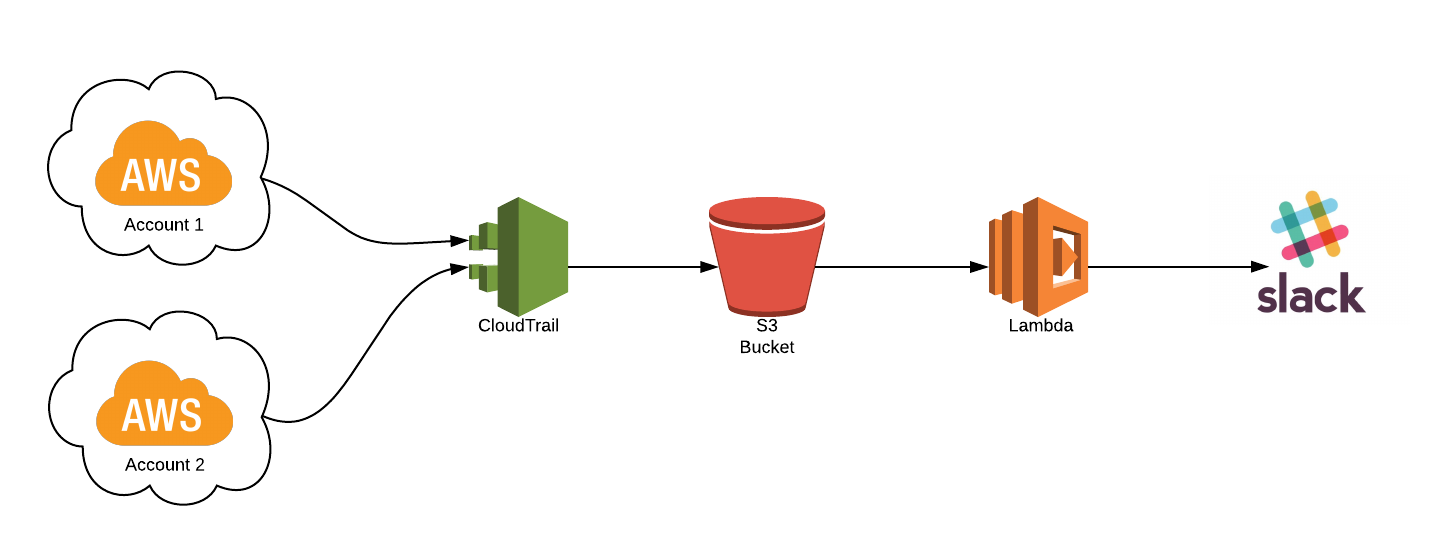
For every change in our environment, we are checking who made the change via a userAgent field in every event representing the event’s source. We then send the event information to a dedicated Slack channel. At first, we only captured events that were originated from “console.ec2.amazonaws.com” to track changes that were done through our AWS Console.

Alignment Through Automation
We chose to solve this problem is by automating the process by going through all of our Terraform repository and running the `terraform plan` on every state we have. in return, we get an indication of the state’s state (pun intended):
- Code 0: Succeeded, there is no diff
- Code 1: State error
- Code 2: Succeeded, but there is a diff
The process runs every morning and gives us a daily report of unapplied changes:
Another way we can consume the data (and get more information on specific states) is by creating a file for each state’s output
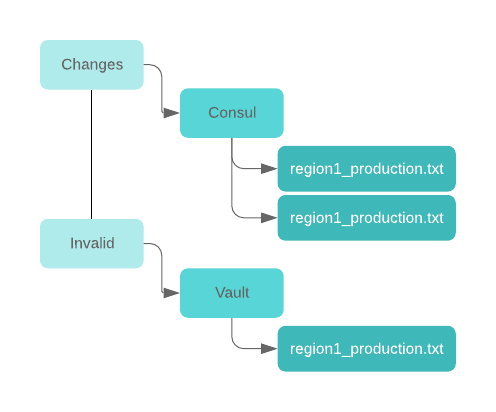
At this point, we were convinced that we must invest time and effort in:
- Educating engineers on how to use terraform. Explaining the importance, demonstrating how they should work with it, and presenting why we believe it can save them time/problems by not being dependent on the availability of a Production Engineer
- The only way this working method is sustainable is by enforcing it through a CI/CD process.
Issue #2 – Dependency management:
Earlier, when we described the Terraform modules structure, we were talking about a module that is using other modules which are also using different modules as building blocks. As you can see, the process can get very complicated.
Here is an example of a module that is using multiple modules as building blocks:
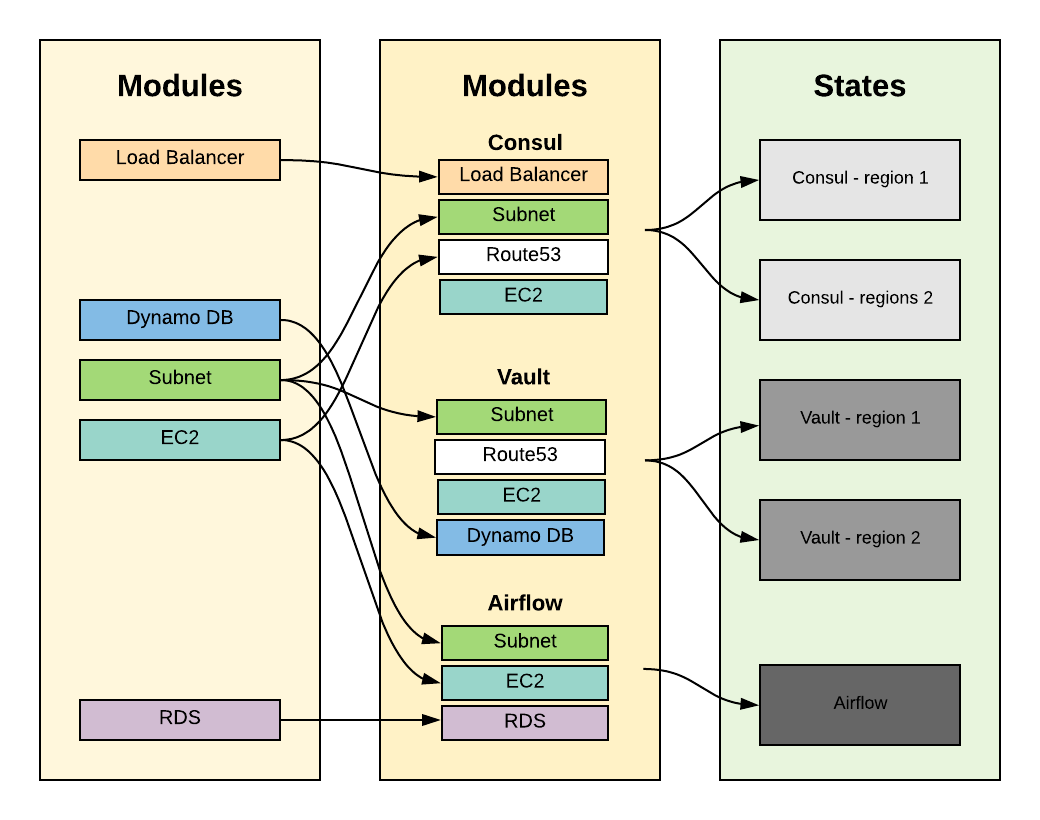
When I’m making a change to the “Subnet” module, what will happen to all the other modules/states that are using it? What if this module is so common that it affects 80% of my environment without me even being aware of it?
Eventually, Terraform’s dependency graph is a DAG (directed acyclic graph) which means we can map every change’s blast radius. The dependency graph is finite and has no directed cycles.
Here’s an example:
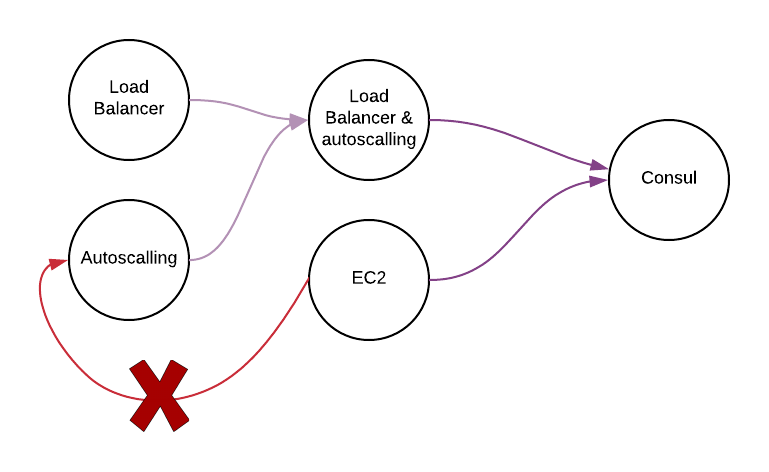
We can detect that the graph is a finite directed graph with no directed cycles. We needed to keep the relationship when we are creating the state.
By having a dependency graph I can analyze which states and modules are affected by each change that is being made.
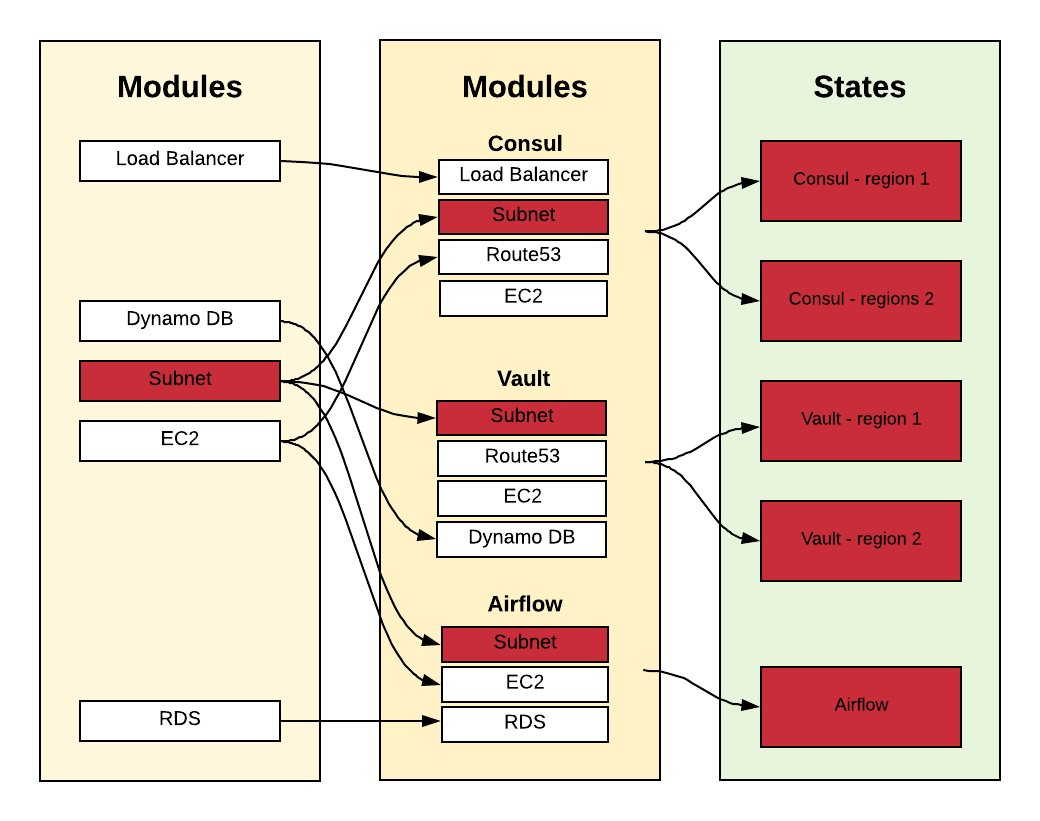
Think about it, we have 500~ states and the number increases every day. How can we track all those changes and see how they affect the entire system?
By implementing a CI flow, we were able to see what is going to happen for each commit/push and act accordingly.
The Solution
We have created a process that will go over all of our Terraform repositories, parse and map the HCL files, and create a dependency graph:

For every commit/push to our Terraform repository, we run this process which will eventually compare the files that were changed to the master branch and send that list of changes to our process.
The process then detects all of the affected states and runs the `terraform plan` to see the actual changes.
Since we are using GitLab, we are using the GitLab CI Runner infrastructure to enforce this:
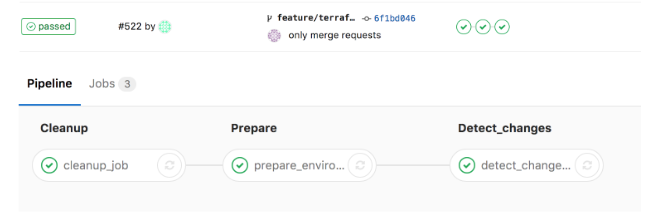
Since we are using this process to analyze every commit, it is widely adopted and gives us much more visibility into the changes that are going to be made to our environment.
What’s next?
Now that we have the CI process in place, we can focus on the CD part which will allow us to apply all of the changes automatically. Of course, this is only the beginning and there’s a lot of challenges here, but, hey, that’s what we do. 🙂
Thanks
About the Author
With years of experience in Software Development and working with some of the biggest corporations in Israel, Elad Kaplan is a Production Engineer at SimilarWeb, where he is able to combine his passion for building infrastructure and writing code.